
Currently Empty: $0.00


LLM
Swarm Intelligence & LLMs in Trading: Two-Agent Reinforcement Learning for Smart Market Decisions
Applying Large Language Models (LLMs) to Trading: A Comprehensive Two-Agent Decision Framework
In recent years, the application of Artificial Intelligence (AI) in financial markets has seen remarkable growth. Among the AI tools, Large Language Models (LLMs) have emerged as versatile agents capable of reasoning, pattern recognition, and decision-making. When combined with reinforcement learning (RL) and multi-agent intelligence, LLMs can transform trading systems from static rule-based algorithms into adaptive, learning-driven frameworks. One particularly promising approach is a two-agent LLM system designed to analyze market signals, generate potential trading actions, and select optimal decisions while balancing risk and reward.
1. Overview of the Two-Agent LLM Trading Model
The proposed system leverages the strengths of multiple AI agents in a structured yet flexible manner. Instead of a single model making all trading decisions, we design two specialized LLM agents, each focused on a distinct part of the trading workflow:
- Agent 1: Focuses on market analysis and generates a broad range of potential trading actions.
- Agent 2: Evaluates the options produced by Agent 1, considering additional constraints, and selects the most promising decision for execution.
This division of labor allows the system to mimic the intelligence found in natural swarms (like bees or birds), where individual members explore various possibilities while a meta-agent coordinates optimal behavior. This approach is particularly useful in the high-stakes, rapidly changing environment of financial markets.
1.1 Agent 1: Candle Analysis & Decision Vector Generation
Agent 1 serves as the analytical engine of the system. Its primary responsibility is to process and interpret complex market data. Key functions include:
- Market Data Analysis: Agent 1 ingests historical and real-time market information, including candlestick patterns, volume trends, moving averages, RSI, MACD, and other technical indicators.
- Decision Vector Output: Rather than producing a single action, Agent 1 generates a decision vector. This vector contains multiple candidate trading actions—buy, sell, hold, or even fractional positions—each associated with a confidence score or probability. For example, a vector might suggest 60% confidence for a buy, 30% hold, and 10% sell.
- Exploratory Strategy Simulation: By generating multiple candidate decisions simultaneously, Agent 1 explores a diverse set of potential market responses, functioning as a “swarm of internal strategies” that can be evaluated for effectiveness.
Through this process, Agent 1 provides a rich set of candidate actions that reflect both historical trends and dynamic market movements, forming the foundation for the next layer of decision-making.
1.2 Agent 2: Decision Selection & Optimization
Agent 2 acts as the meta-decision maker or “optimizer” in this system. Its responsibilities include:
- Candidate Evaluation: Agent 2 receives the decision vectors from Agent 1 and evaluates the expected reward of each candidate action.
- Contextual Risk Assessment: It incorporates additional market context, such as portfolio exposure, maximum allowable drawdown, volatility levels, and other risk management rules.
- Action Selection: By weighing both expected reward and risk, Agent 2 consolidates multiple options into a single actionable trading decision. This ensures that the system not only pursues profit opportunities but also manages potential losses effectively.
In essence, Agent 2 transforms the diverse, exploratory outputs of Agent 1 into a coherent, risk-aware trading strategy, making it a critical component for optimizing long-term performance.
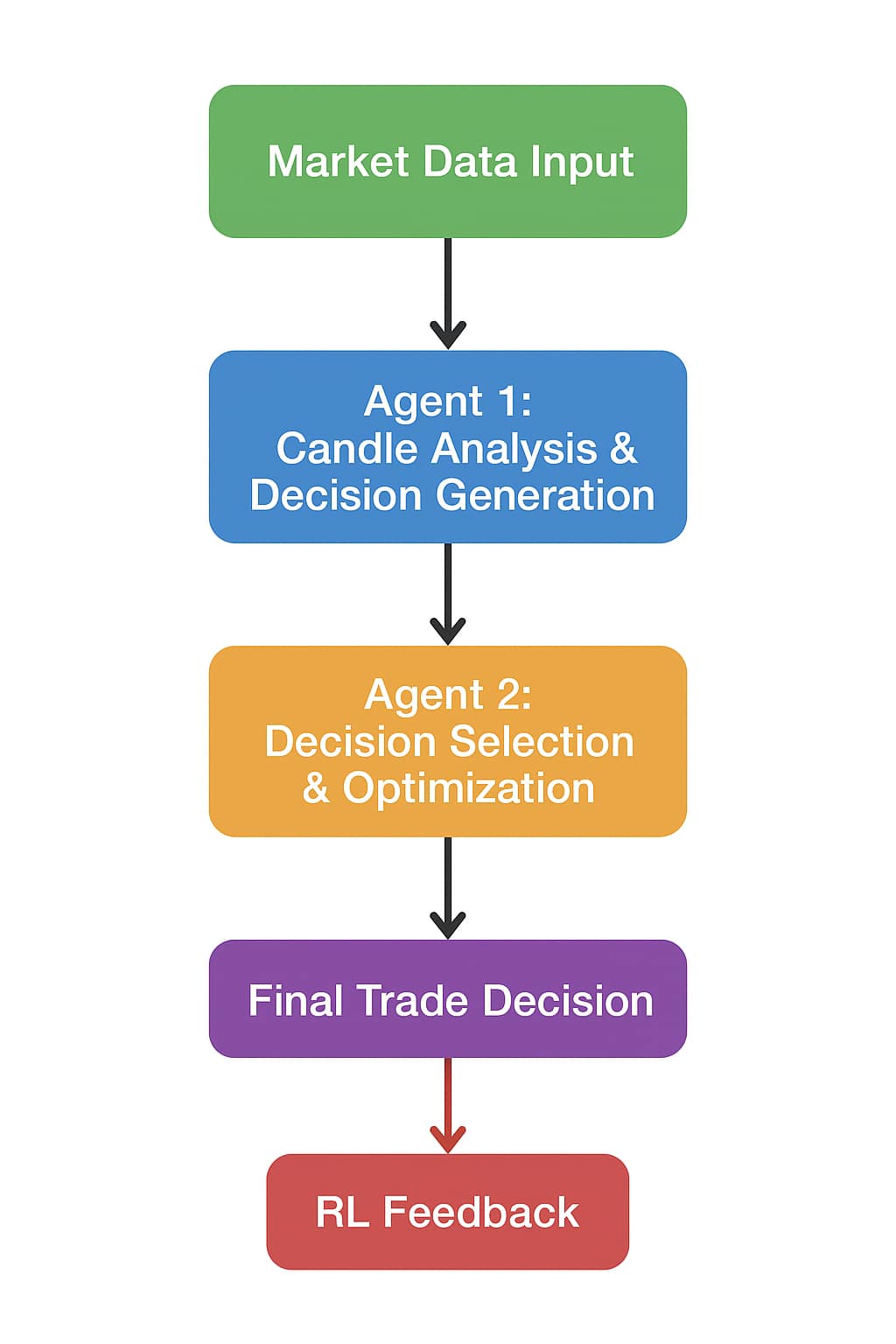
2. Workflow of the Two-Agent System
The interaction between the two agents can be visualized as a structured feedback loop:
- Market Data Input: Historical and real-time market data, including candlestick charts, technical indicators, and news sentiment (if integrated), are fed into Agent 1.
- Decision Vector Generation: Agent 1 outputs multiple candidate trading actions with associated confidence scores.
- Meta-Evaluation: Agent 2 evaluates each candidate, considering additional constraints like portfolio balance, maximum risk exposure, and market volatility.
- Final Decision Execution: The system executes the trading action chosen by Agent 2.
- Reinforcement Learning Feedback: The profit or loss from executed trades serves as a reward signal. Both agents update their internal policies:
- Agent 1 refines its decision vector generation process, learning which patterns and indicators are most predictive.
- Agent 2 improves its selection algorithm, enhancing its ability to balance reward and risk.
- Iteration: The system repeats this loop for every new trading interval—such as every minute, hourly, or daily candle—allowing continuous adaptation to changing market conditions.
This workflow creates a dynamic, self-improving trading system where exploration (Agent 1) and exploitation (Agent 2) are tightly integrated.
3. Advantages of the Two-Agent LLM Model
This architecture offers several key benefits over traditional single-agent trading systems:
- Diversified Exploration: By generating multiple candidate actions, Agent 1 reduces the risk of overfitting to historical patterns and improves the system’s ability to adapt to new market conditions.
- Risk-Aware Optimization: Agent 2 ensures that trading decisions consider portfolio constraints and risk management rules, preventing reckless trades that might occur if only raw predictions were used.
- Emergent Learning: With reinforcement learning feedback, both agents improve continuously. Agent 1 becomes better at generating meaningful candidate actions, and Agent 2 becomes more skilled at selecting the highest-value action.
- Modular and Scalable Design: Each agent can be independently upgraded. For example, Agent 1 could integrate new technical indicators or news sentiment analysis without needing to retrain Agent 2, and vice versa.
- Multi-Layered Decision Making: The separation between analysis and decision selection allows for a more nuanced approach than traditional rule-based or single-model systems.
4. Extensions and Future Enhancements
Once the two-agent framework is established, several enhancements can further improve performance:
- Multi-Agent Swarm Systems: Multiple Agent 1 models can work in parallel to generate a larger set of candidate actions, creating a swarm intelligence effect. This can increase diversity and robustness of trading decisions.
- Dynamic Reward Shaping: Reward functions can incorporate metrics beyond profit/loss, such as risk-adjusted returns, Sharpe ratios, or maximum drawdown minimization.
- Hybrid Models: Traditional quantitative trading algorithms can be combined with LLM agents to leverage both classical statistical methods and modern AI reasoning.
- Simulation and Self-Play: Agents can simulate trades on historical or synthetic market data (paper trading) to refine strategies before live deployment, reducing risk of catastrophic mistakes in real markets.
- Integration of Alternative Data: Sentiment analysis from social media, news articles, and macroeconomic reports can be incorporated into Agent 1’s analysis to capture hidden market drivers.
5. Illustrative Example
Consider a scenario where the market is showing mixed signals: a bullish candlestick pattern but declining volume. Agent 1 might generate a decision vector such as:
- Buy – 40% confidence
- Hold – 50% confidence
- Sell – 10% confidence
Agent 2 then evaluates these options, taking into account the portfolio’s current exposure, risk limits, and volatility. It might decide that holding the position aligns best with risk-adjusted returns, even though a buy signal had slightly higher raw confidence. After execution, the trade outcome feeds back as reinforcement learning rewards, improving both agents’ future performance.
Conclusion
The two-agent LLM framework represents a significant step forward in AI-driven trading. By clearly separating analysis and decision selection, the system achieves a balance between exploration and optimization. Iterative learning through reinforcement signals enables the agents to adapt dynamically to market changes, potentially discovering emergent strategies that enhance profitability while managing risk. This approach not only demonstrates the versatility of LLMs but also illustrates how multi-agent AI systems can tackle complex, uncertain environments beyond traditional algorithmic solutions.
Overall, integrating LLMs in trading through a two-agent or multi-agent system provides a modular, scalable, and intelligent framework capable of evolving alongside the markets it operates in. The combination of diverse strategy generation, meta-level optimization, and reinforcement learning creates a powerful paradigm for next-generation automated trading systems.
jlvs
Yo, peeped jlvs and things there are really well made, might be awesome! If looking for something cool, try checking it out jlvs.